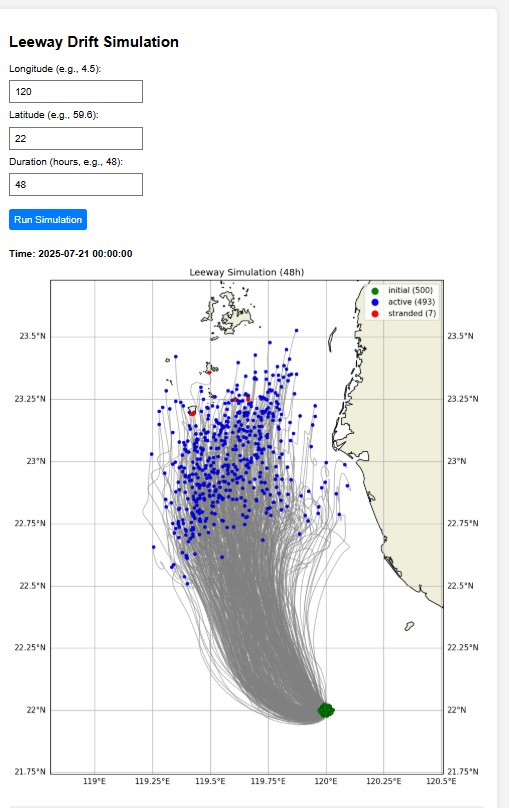
Man over board model
comments powered by Disqus
從零開始建立人員落水軌跡預測模型(一)NETCDF檔案介紹
- 概述 (What & Why)
NetCDF 是一套為「科學陣列型資料」設計的 自描述 (self-describing)、跨平台 (portable)、可擴充 (extensible) 的資料模型與檔案格式,同時也包含一組 API 函式庫。典型應用領域包含:氣象、海洋、氣候、遙測、模式模擬(如大氣模式、海流、浪場)等。
- 核心資料模型 (Classic Data Model)
| 元素 | 意義 | 特點 |
|---|---|---|
| Dimension(維度) | 定義陣列的軸長度與名稱,例如 time, lat, lon, depth |
可標記一個為 unlimited(無界/可增長),常用於時間序列 |
| Variable(變數) | 具名的 N 維陣列,使用一組已定義維度,並附屬屬性 | 儲存實際科學數值,如 temperature(time, depth, lat, lon) |
| Attribute(屬性) | 附掛在檔案 (global) 或變數上的「鍵值對」型 metadata | 描述單位、長描述、縮放係數、缺值等 |
| Data(資料) | 各變數的陣列值本體 | 支援多種基本型別 (byte, char, short, int, float, double, int64, etc.) |
- NetCDF Header 範例與逐行解釋
原始 Header
netcdf example {
dimensions:
time = UNLIMITED ; // (10 currently)
lat = 181 ;
lon = 360 ;
variables:
double time(time) ;
time:units = "hours since 2025-07-20 00:00:00" ;
time:calendar = "gregorian" ;
float lat(lat) ;
lat:units = "degrees_north" ;
float lon(lon) ;
lon:units = "degrees_east" ;
float temperature(time, lat, lon) ;
temperature:long_name = "Sea surface temperature" ;
temperature:units = "K" ;
temperature:_FillValue = -9999.f ;
temperature:scale_factor = 0.01f ;
temperature:add_offset = 273.15f ;
// global attributes:
:title = "Demo SST" ;
:history = "2025-07-20T12:00:00Z created" ;
}
逐段說明
維度宣告
dimensions:
time = UNLIMITED ; // (10 currently)
lat = 181 ;
lon = 360 ;
- 宣告 3 個維度:
time、lat、lon。 time = UNLIMITED表示此維度可增長(appendable),目前已有 10 筆(索引 0..9)。lat = 181、lon = 360為固定長度。例如:lat可能為 -90 到 90(含端點,共 181 個點,步距 1°);lon可能為 0 到 359(共 360 個點)。
時間變數
double time(time) ;
time:units = "hours since 2025-07-20 00:00:00" ;
time:calendar = "gregorian" ;
time(time):1 維時間座標變數。units採 CF 規範:「<時間單位> since <參考時間>」。此處表示「自 2025-07-20 00:00:00 起算的小時數」。- 例:
time[0] = 0→ 2025-07-20 00:00 time[1] = 6→ 2025-07-20 06:00
- 例:
calendar="gregorian"指定日曆系統。
經緯度座標變數
float lat(lat) ;
lat:units = "degrees_north" ;
float lon(lon) ;
lon:units = "degrees_east" ;
- 座標變數(coordinate variables):名稱與維度相同。
- 提供每個格點的地理位置(緯度、經度)。
資料變數
float temperature(time, lat, lon) ;
temperature:long_name = "Sea surface temperature" ;
temperature:units = "K" ;
temperature:_FillValue = -9999.f ;
temperature:scale_factor = 0.01f ;
temperature:add_offset = 273.15f ;
temperature為 3 維資料:time × lat × lon。- 使用「打包(packed)」策略:以
scale_factor與add_offset壓縮存放範圍。- 解碼:
physical_value = scale_factor * stored_value + add_offset。 - 例:
stored = 2000→0.01 * 2000 + 273.15 = 293.15 K。
- 解碼:
_FillValue = -9999.f:缺值標記;讀取後通常轉換為NaN。long_name與units為語意與顯示用 metadata。
全域屬性
:title = "Demo SST" ;
:history = "2025-07-20T12:00:00Z created" ;
title:檔案標題。history:處理沿革;每次加工可附加一段(建議包含時間戳與動作)。
- 對應速查
| 區塊 | 重點 | 補充 |
|---|---|---|
| dimensions | 定義各軸大小,UNLIMITED 允許追加 |
一檔可有 0 或多個 unlimited(建議僅 1 個) |
| time 變數 | 時間軸與日曆 | 使用 CF 規範「units + calendar」 |
| lat/lon | 空間座標 | 可搭配 standard_name="latitude" 等 |
| temperature | 主資料陣列 | 打包機制節省空間 |
| global attributes | 整體描述與追溯 | history 建議 ISO 8601 |
- Packed value 解碼範例(Python)
physical = scale_factor * stored + add_offset
physical[stored == fill_value] = np.nan
需要再擴充成 CF Conventions 教學、或輸出成 PDF / Word 版本,可再告訴我。
6. 使用 xarray 讀取與操作 NetCDF
以下示範使用 xarray(結合 netCDF4 或 h5netcdf 後端)讀取、檢視、分析與寫回 NetCDF 的典型流程。
6.1 安裝
pip install xarray netCDF4 cftime dask[complete]
# 若需要壓縮或平行最佳化,可再安裝 zarr, h5netcdf 等
6.2 基本開檔
import xarray as xr
ds = xr.open_dataset('example.nc') # 延遲讀取 (lazy);僅讀 header/metadata
print(ds) # 類似 ncdump -h + 變數概觀
open_dataset預設是 lazy:真正的資料直到運算或.load()才讀入記憶體。
6.3 取出變數與座標
t = ds['temperature'] # DataArray
lat = ds['lat']
lon = ds['lon']
print(t.dims, t.shape) # ('time','lat','lon'), (10,181,360)
6.4 自動解碼時間、scale_factor 與缺值
xarray 預設會依 CF Conventions 自動:
- 將
time轉為datetime64或cftime物件。 - 套用
scale_factor/add_offset。 - 將
_FillValue/missing_value轉為NaN。
可停用:xr.open_dataset('example.nc', decode_times=False, mask_and_scale=False)。
6.5 選取與切片
# 依座標值切片(最近鄰或對齊)
subset = t.sel(time='2025-07-20T06:00:00', lat=slice(-10,10), lon=slice(120,150))
# 依索引切片
t0 = t.isel(time=0)
6.6 計算(懶加速)
# 平均一段時間與空間(仍 lazy)
mean_equatorial = t.sel(lat=slice(-5,5)).mean(dim=('time','lat'))
# 觸發實際計算
result = mean_equatorial.compute() # 或 .load()
若安裝與設定 Dask,xarray 會自動用 Dask array,便於大檔案平行/分塊運算。
6.7 設定 Chunk(適合大檔案)
ds = xr.open_dataset('example.nc', chunks={'time': 50})
chunks對應 Dask 分塊大小;與 NetCDF chunk 不同,但影響執行時分佈計算。- 建議 time 維度 chunk 為常用分析窗口倍數。
6.8 多檔拼接 (Concatenation) 與合併
# 多檔沿 time 座標自動串接
ds_all = xr.open_mfdataset('var_2025_0*.nc', combine='by_coords', parallel=True,
data_vars='minimal', coords='minimal', compat='override')
常見參數:
| 參數 | 作用 |
|---|---|
combine='by_coords' |
依座標值(如 time)對齊拼接 |
parallel=True |
啟用 Dask 平行 |
data_vars='minimal' |
避免重複合併變數屬性衝突 |
compat='override' |
屬性衝突時採第一份 |
6.9 去除重複時間與排序
if 'time' in ds_all.coords:
ds_all = ds_all.sortby('time')
_, idx = xr.unique(ds_all.time, return_index=True)
if len(idx) != ds_all.sizes['time']:
ds_all = ds_all.isel(time=idx.sortby(idx))
6.10 加入新計算結果
ds_all['temp_anomaly'] = ds_all.temperature - ds_all.temperature.mean('time')
新增的
DataArray會自動繼承對齊座標。
6.11 寫回 NetCDF
encoding = {
'temperature': {
'zlib': True, 'complevel': 4, 'shuffle': True,
# 指定 chunksizes (影響最終 NetCDF 物理 chunk)
'chunksizes': (50, ds_all.dims['lat'], ds_all.dims['lon'])
},
'temp_anomaly': {'zlib': True, 'complevel': 4, 'shuffle': True}
}
ds_all.to_netcdf('merged_with_anomaly.nc', encoding=encoding)
注意:
chunksizes是寫入 NetCDF 物理 chunk(與open_dataset(..., chunks=...)的記憶體分塊不同)。- 設定壓縮層級 1–6 通常平衡速度與壓縮比。
6.12 與 Pandas 互動
# 取某經緯點時間序列,轉為 Pandas Series
pt_series = ds_all.temperature.sel(lat=0.0, lon=140.0, method='nearest')
ser = pt_series.to_pandas()
6.13 常見錯誤排查
| 情況 | 原因 | 解法 |
|---|---|---|
ValueError: conflicting sizes for dimension 'time' |
多檔 time 維度無法對齊 | 改用 combine='nested' + 手動指定 concat_dim 或檢查時間座標值 |
| 時間無法解析 (NaT) | calendar 不支援 datetime64 |
使用 xr.open_dataset(..., use_cftime=True) |
| 記憶體不足 | .load() 讀入太大 |
保持 lazy,使用 .compute() 只在需要時觸發;調整 chunks |
| 運算很慢 | chunk 不佳或過多小檔 | 重新設定 chunk;先用 NCO/CDO 合併減少檔案數 |
6.14 快速範例(從讀到分析再輸出)
import xarray as xr
# 1. 讀多檔
files = 'var_2025_0*.nc'
ds = xr.open_mfdataset(files, combine='by_coords', chunks={'time': 48})
# 2. 時間排序
ds = ds.sortby('time')
# 3. 計算季平均 (假設 time 是 hourly 資料)
season_mean = ds.temperature.resample(time='3M').mean()
# 4. 儲存結果
season_mean.to_netcdf('temperature_3M_mean.nc')
6.15 小抄 (Cheat Sheet)
| 任務 | 做法 | 備註 |
|---|---|---|
| 開檔 | xr.open_dataset() |
lazy, metadata only |
| 多檔 | xr.open_mfdataset() |
自動拼接座標 |
| 選取 | .sel() / .isel() |
值 vs 索引 |
| 聚合 | .mean() .sum() .resample() |
支援多維 |
| 新變數 | ds['new']=... |
座標自動對齊 |
| 寫檔 | .to_netcdf(encoding=...) |
控制壓縮/chunk |
| 去重 | xr.unique + isel |
需排序先 |
| 時間重抽樣 | .resample(time='D').mean() |
需時間為 datetime 類型 |
| 轉 Pandas | .to_pandas() |
只適用 1D 座標 |
若需要:我可以再加上 Zarr 雲端存取流程、平行 Dask 設定 或 CF 規範標準名稱補充,告訴我即可。